

Job id : 161490
Database Engineer
Database Engineer

 Hyderabad
Hyderabad

 2 days ago
2 days ago
 39 Applied
39 Applied
JOB ID:161490
Job details
Job Type
 Full Time
Full Time
Functional Area
Database Administrator/ Data warehousing
Industry
IT-Software/Software Services
Education
Not Specified
Experience Required
 3 - 5 Yrs
3 - 5 Yrs
Salary
 15 - 18 Lakhs
15 - 18 Lakhs
Key Skills Required
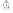 pyspark, sql, big data analytics, python
pyspark, sql, big data analytics, python
Other Skills Required
Languages
English
Job Description
The Sr. Analytics Engineer would provide technical expertise in needs identification, data modeling, data movement, and transformation mapping (source to target), automation and testing strategies, translating business needs into technical solutions with adherence to established data guidelines and approaches from a business unit or project perspective.
- Understands and leverages best-fit technologies (e.g., traditional star schema structures, cloud, Hadoop, NoSQL, etc.) and approaches to address business and environmental challenges.
- Provides data understanding and coordinates data-related activities with other data management groups such as master data management, data governance, and metadata management.
- Actively participates with other consultants in problem-solving and approach development.
- Provide a consultative approach with business users, asking questions to understand the business need and deriving the data flow, and conceptual, logical, and physical data models b
The Sr. Analytics Engineer would provide technical expertise in needs identification, data modeling, data movement, and transformation mapping (source to target), automation and testing strategies, translating business needs into technical solutions with adherence to established data guidelines and approaches from a business unit or project perspective.
- Understands and leverages best-fit technologies (e.g., traditional star schema structures, cloud, Hadoop, NoSQL, etc.) and approaches to address business and environmental challenges.
- Provides data understanding and coordinates data-related activities with other data management groups such as master data management, data governance, and metadata management.
- Actively participates with other consultants in problem-solving and approach development.
- Provide a consultative approach with business users, asking questions to understand the business need and deriving the data flow, and conceptual, logical, and physical data models based on those needs. Perform data analysis to validate data models and to confirm the ability to meet business needs.
- Assist with and support setting the data architecture direction, ensuring data architecture deliverables are developed, ensuring compliance to standards and guidelines, implementing the data architecture, and supporting technical developers at a project or business unit level.
- Coordinate and consult with the Data Architect, project manager, client business staff, client technical staff, and project developers in data architecture best practices and anything else that is data-related at the project or business unit levels.
- Work closely with Business Analysts and Solution Architects to design the data model satisfying the business needs and adhering to Enterprise Architecture.
- Coordinate with Data Architects, Program Managers and participate in recurring meetings.
- Help and mentor team members to understand the data model and subject areas.
- Ensure that the team adheres to best practices and guidelines.
- Strong working knowledge ofat least 3 yearsof Spark, Java/Scala/Pyspark, Kafka, Git, Unix / Linux, and ETL pipeline designing.
- Experience with Spark optimization/tuning/resource allocations
- Excellent understanding of IN memory distributed computing frameworks like Spark and its parameter tuning, writing optimized workflow sequences.
- Experience of relational databases (e.g., PostgreSQL, MySQL) and NoSQL databases (e.g., Redshift, Bigquery, Cassandra, etc).
- Familiarity with Docker, Kubernetes, Azure Data Lake/Blob storage, AWS S3, Google Cloud storage, etc.
- Have a deep understanding of the various stacks and components of the Big Data ecosystem.
- Hands-on experience with Python is a huge plus
About Company
https://themoderndatacompany.com/
Recommended Companies



Recommended Events


